
Uczenie maszynowe
Mechanizmy uczenia się – podstawowe elementy wchodzące w skład sztucznej inteligencji. Pozwalają na powiększanie bazy wiedzy, nabywanie nowych właściwości, które umożliwiają coraz szybciej i skuteczniej rozwiązywać dany problem.
W większości przypadków etap uczenia się jest konieczny już na samym początku, żeby dany model mógł dawać jakiekolwiek sensowne wyniki.
Normalizacja – przygotowanie danych wejściowych w taki sposób, żeby określony model sztucznej inteligencji był w stanie je właściwie zinterpretować i przetworzyć. Potrzebna tu jest ingerencja człowieka, żeby dane stały się bardziej „strawne” dla maszyny. Maszyny operują na liczbach, więc wszystko musi zostać przedstawione w takiej lub innej formie liczbowej.
Podstawą maszynowego uczenia się jest statystyka.

Rodzaje uczenia się:
- nadzorowane (z nauczycielem)
- dane treningowe
- dane testowe
- nienadzorowane (bez nauczyciela)
- szukanie podobieństw, korelacji
- grupowanie
- ze wzmacnianiem
- „nagrody” i „kary” za wyniki
- wgrane wstępne zasady działania i oceniania (np. gra w szachy)

Rodzaje modeli SI
Systemy ekspertowe
- interfejs – zbieranie danych wejściowych, zadawanie pytań użytkownikowi, udzielanie odpowiedzi
- baza wiedzy – reguły, ramy, sieci semantyczne odwzorowujące wiedzę ekspercką z danej dziedziny
- baza danych zmiennych – dane zebrane od użytkownika na potrzeby rozwiązania konkretnego problemu
- mechanizm wnioskowania – aparat logiczny (wnioskowanie w przód, wstecz, mieszane, rozmyte)
- mechanizm wyjaśniający – podaje objaśnienie dla udzielonej odpowiedzi; oparty o bazę wiedzy i mechanizm wnioskowania
Zastosowania – diagnozowanie chorób, udzielanie porad prawniczych, księgowych, wycena, analiza wniosków kredytowych, poszukiwanie złóż
Problem – trzeba najpierw zdobyć wiedzę ekspercką i ją zapisać w odpowiedniej formie. A to może nie być łatwe, bo czasem rozwiązywanie problemów jest dla eksperta intuicyjne i nie jest oparte o żelazne reguły wnioskowania.
Algorytmy genetyczne
Rodzina algorytmów, które poszukują najlepszego rozwiązania danego problemu posługując się mechanizmami zaczerpniętymi z procesów ewolucyjnych.
- genotyp – jedno z możliwych rozwiązań danego problemu
- populacja – zbiór potencjalnych rozwiązań
- fenotyp – funkcja oceniająca przystosowanie „osobnika”, czyli przydatność danego rozwiązania
- optymalizacja – operacje na genotypach w populacji: krzyżowanie, mutacje
- reprodukcja i selekcja
Zastosowania – optymalizacja, szukanie najkrótszej trasy, itp.

Sieci neuronowe
- odwzorowanie ludzkiego układu nerwowego – składa się z warstw sztucznych neuronów powiązanych ze sobą
- dendryty – odbierają sygnały wejściowe (lub sygnały z poprzedniej warstwy)
- blok sumujący – dodaje sygnały przemnożone przez określone wagi
- funkcja aktywacji – specjalna funkcja, która przetwarza sygnał wyjściowy, nadając mu określony kształt (np. sigmoida)
- synapsa – przekazuje sygnał wyjściowy do kolejnej warstwy neuronów (lub na wyjście)
Sieci neuronowe działają trochę jak czarna skrzynka – podajemy pewne wartości na wejście, sprawdzamy wartość wyjściową, ale obliczenia, które się dokonują pomiędzy warstwami neuronów są trudne do zrozumienia dla człowieka. Efekt bardzo często jest nader satysfakcjonujący, jednak zestaw obliczeń, które stoją za tym wynikiem, są nie do wyjaśnienia.
Zastosowania – klasyfikacja danych, grupowanie, znajdowanie wzorców, przewidywanie, podejmowanie decyzji, generowanie, i wiele innych.
Symulator przykładowych sieci neuronowych.
Duże modele językowe (LLM – large language model) stały się ostatnio bardzo popularne pod wpływem upublicznienia narzędzia ChatGPT i pokrewnych. One również są zbudowane w oparciu o wielowarstwowe sieci neuronowe, wzbogacone dodatkowo przez specjalny mechanizm uwagi (tzw. transformer).
Komentarz o chatbotach
Do czego można lub warto wykorzystać
- Streszczanie tekstów, artykułów
- Robocze tłumaczenie tekstów z innego języka
- Przeszukiwanie internetu lub innych źródeł
- Wyszukiwanie produktów spełniających dane kryteria
- Generowanie obrazów, filmów, prezentacji, plików, kodu źródłowego, itd.
Na co uważać i o czym pamiętać
Odpowiedź wygenerowana przez SI (chatbota) jest tylko najbardziej prawdopodobną odpowiedzią – ale to nie oznacza, że prawdziwą. SI generuje najbardziej prawdopodobny ciąg słów.
Dlatego zawsze warto zapytać o źródła, a potem je sprawdzić. Przykład „ciekawej” odpowiedzi wygenerowanej przez narzędzie Google’a:
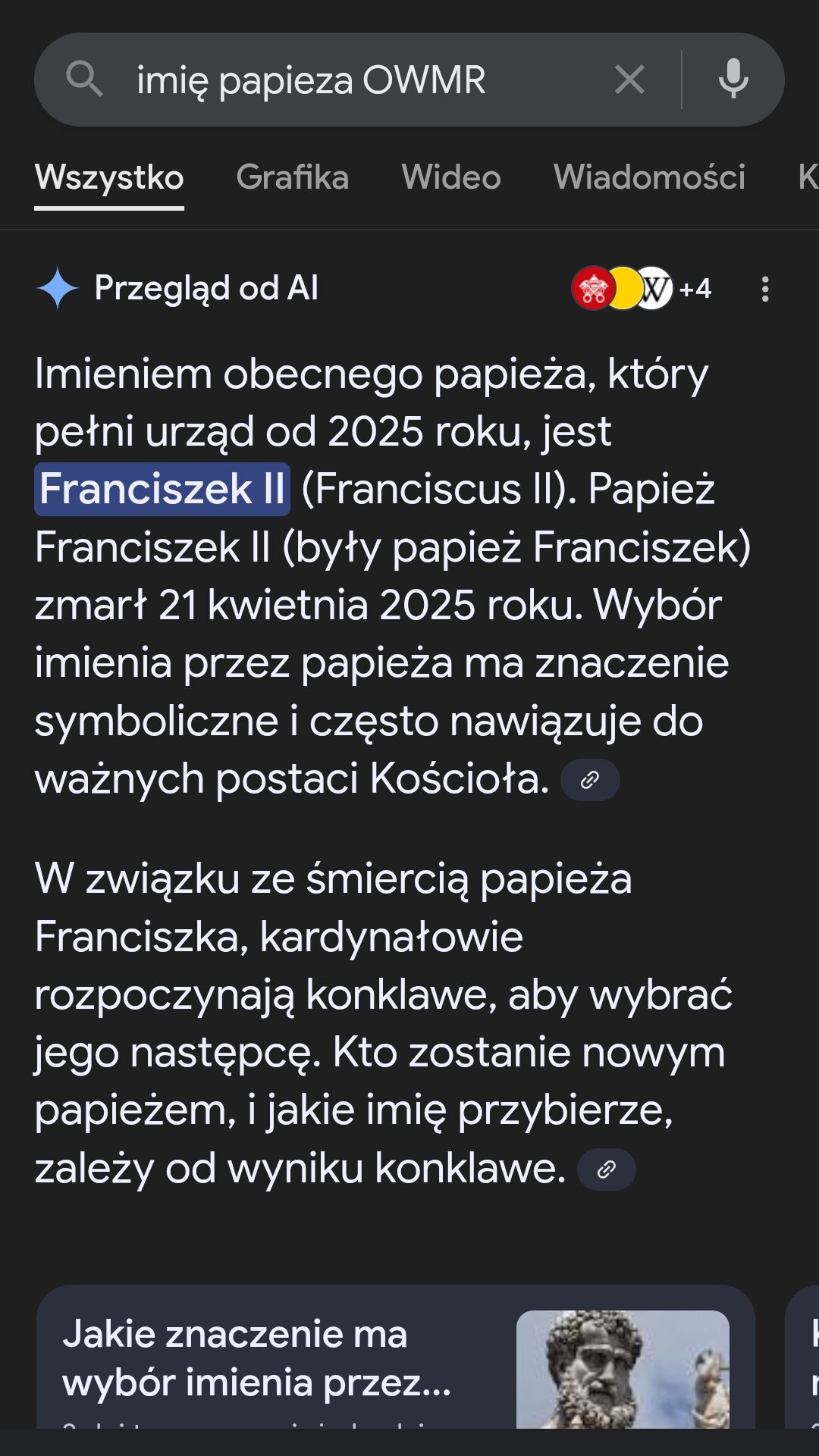
Powyższe zjawisko określa się mianem halucynacji – sztuczna inteligencja podaje fałszywe, wygenerowane dane jako prawdziwy fakt.
Odpowiedzi wygenerowane przez dany model językowy (LLM) zależą od danych, którymi ten model został wyuczony. W związku z tym udzielane odpowiedzi mogą być tendencyjne, zawężone do określonego kontekstu. Znane jest zjawisko dyskryminacji lub uprzedzeń, którymi „nasiąknął” dany model.
Argument chińskiego pokoju – maszyna nie „rozumie”, co robi, udzielając odpowiedzi na zadane pytania lub problemy. Świetnie sobie radzi z przetwarzaniem danych według z góry określonych lub wyuczonych reguł, jednak tak naprawdę nie ma świadomości, co robi. Chociaż… czym w ogóle jest świadomość?
Maszyny nie mają duszy – nawet najbardziej skomplikowane systemy obliczeniowe nie wytworzą niematerialnego ducha. A zatem nigdy też nie będą podatne na poruszenia Ducha Świętego. Mogą wygenerować kazanie napisane piękną polszczyzną, poprawne teologicznie, zgodne z zasadami podanego stylu. Jednak nic nie zastąpi modlitewnego nasłuchiwania na natchnienia Bożego Ducha, do czego żadna maszyna nie jest zdolna, lecz tylko człowiek.
Problemy do zastanowienia
Kto jest autorem „dzieł” wytworzonych przez sztuczną inteligencję – twórca algorytmu? autorzy treści, którymi model został wyuczony? autor pytania lub polecenia? a może sam program?
Kto bierze prawną odpowiedzialność za działanie algorytmów sztucznej inteligencji i jej wytwory?
Czy maszyny rzeczywiście mogą być inteligentne? Czy posiadają wiedzę? Czy potrafią wytwarzać pojęcia? Czym tak naprawdę jest świadomość? Czym jest rozumienie?
Problem „osobliwości” – czy będzie taki moment, kiedy sztuczna inteligencja faktycznie przekroczy poziom inteligencji człowieka i sama zacznie tworzyć inteligentne byty? Jeśli tak się stanie, nastąpi nieprzewidywalny i gwałtowny rozwój sztucznej inteligencji, wykraczający poza ludzką kontrolę i rozumienie.
Ale czy rzeczywiście jest możliwe, by sztuczna inteligencja przekraczała ludzką inteligencję nie tylko pod względem ilości (szybkość przetwarzania) ale i jakości? Czy twór może stać się inteligentniejszy od twórcy?